Veridge MCP Server
Enables AI assistants to query a project's unified graph (code, documents, decisions) with token-budgeted, ranked context, including focus, impact, and find operations.
README
Veridge
![]()
![]()
![]()
![]()
The always-fresh, low-token map of a whole project — documents, code (down to the function/class), decisions and work sessions — unified in one typed graph, ranked by what matters, and served both to an AI assistant (as the minimal relevant context) and to a human.
Veridge fuses veridical (truthful, verified) with ridge — the crest line that runs through and connects a whole terrain. That's what it builds: the true, always-fresh backbone of how a project fits together — the structural through-line you and your assistant navigate by.
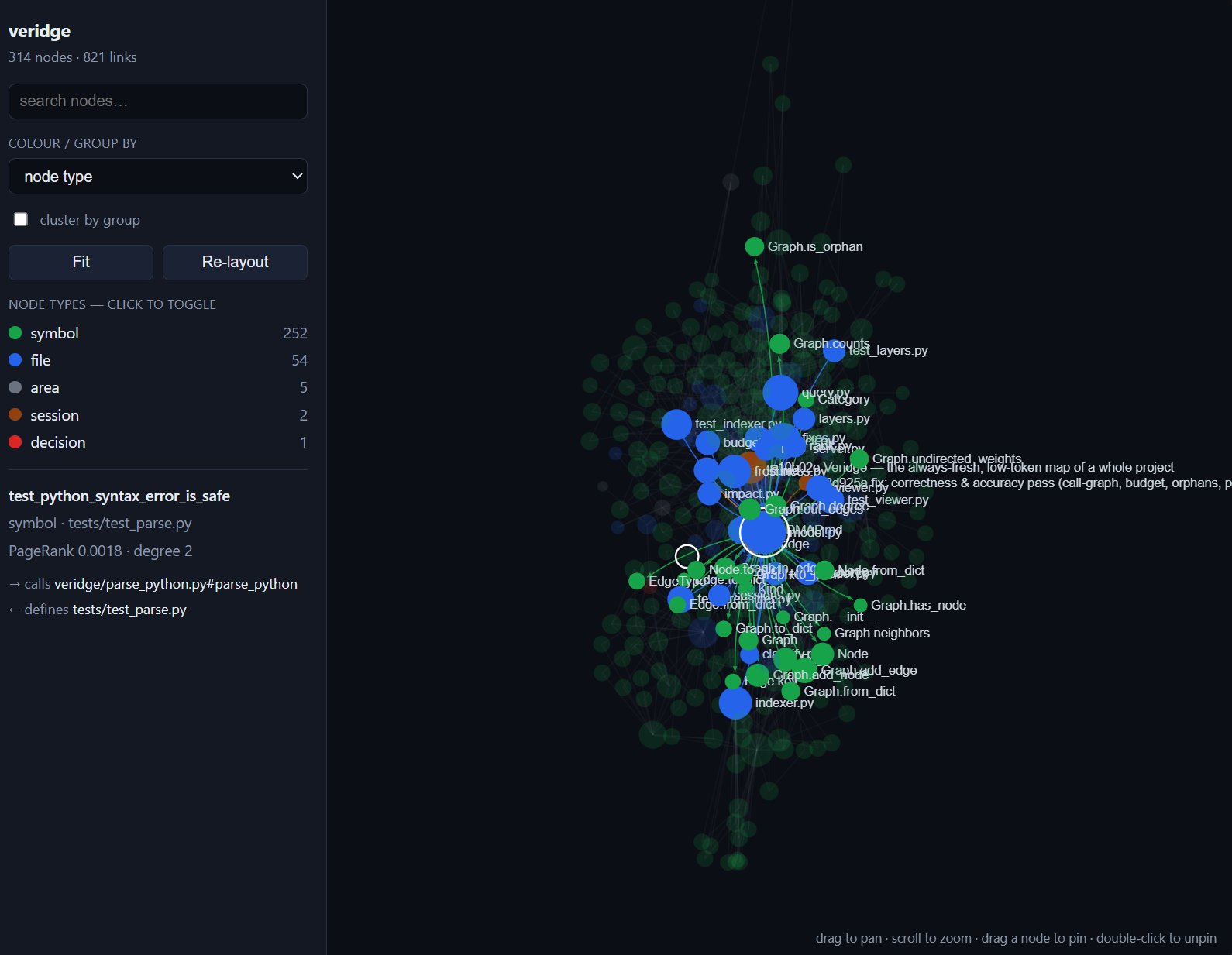
<sub>veridge view . — the self-contained offline viewer (no CDN, no server) on Veridge's own
codebase: files, symbols, areas and sessions in one graph.</sub>
Why it exists
A project's knowledge lives in three places that drift apart: the code, the documents (designs, decisions, notes) and the history of how it got here. As it grows, keeping a mental model of how everything connects gets harder — and an AI assistant loses the thread between one session and the next, so every session restarts by re-reading and re-searching files. That is slow, incomplete, and burns tokens repeatedly.
Veridge builds the project's graph once and keeps it fresh, then answers questions about it in a few hundred tokens. It unifies documents, code (down to the symbol), decisions and sessions in one map, ranks it so an answer is the relevant slice rather than everything, and serves that slice within a token budget — to an AI assistant and to a human alike.
What makes it different
| Pillar | What it means |
|---|---|
| One unified graph | files + symbols (functions/classes) + areas + decisions + git sessions — code, docs and history in a single map. |
| Symbol-level, with a real call graph | Python is parsed with the stdlib ast into a defines/imports/calls graph. Other languages plug in via the optional [treesitter] extra. |
| Ranked by relevance | global PageRank ("what matters in this project") and personalised PageRank ("what matters for this task"). |
| Token-budgeted, task-aware | veridge focus "<task>" returns the minimal relevant subgraph within a token budget — relevant context, not the whole repo. |
| Anti-drift gate | content-hash freshness: refuses to call the map "fine" while something is stale, broken or orphaned. |
| Zero infrastructure | the core runs on the Python standard library alone — no DB, no embeddings, no server. Read-only on your sources. |
| MCP-first | the same ranked, budgeted queries are exposed to MCP-aware assistants behind an optional extra. |
It is not a RAG system: no embeddings, no vector store, no LLM to build the graph. It maps structure and importance, which makes it complementary to RAG and purpose-built for one thing: the cheapest accurate context for orienting on a project.
Install
pip install -e . # from a clone
pip install -e ".[mcp]" # + optional MCP server
pip install -e ".[treesitter]" # + symbol-level JS/TS/Go/Rust/Java parsing
Requires Python 3.10+. Runtime dependencies of the core: none.
Quickstart
veridge build . # index -> .veridge/graph.json (+ manifest)
veridge map . # PageRank-ranked digest: areas, sizes, what matters
veridge focus "<task>" . # the signature query: minimal relevant subgraph, budgeted
veridge impact src/util.py . # blast-radius: what a change here affects (ranked, budgeted)
veridge impact --diff . # blast-radius of your current working changes (vs git HEAD)
veridge tour . # dependency-ordered reading tour of the key files
veridge why src/cli.py src/model.py . # shortest typed path between two nodes
veridge find greet . # find nodes (files or symbols) by name/path
veridge neighbors src/util.py . # a node and its typed connections
veridge view . # write an offline, self-contained graph viewer (HTML)
veridge gate . # anti-drift: broken refs, stale files, orphans
veridge watch . # rebuild automatically when files change (poll loop)
veridge install-hook . # git post-commit hook that keeps the map fresh
veridge export . # export the graph (jgf / dot / native) for other tools
veridge stats . # counts by node/edge type
veridge map also groups files by architectural layer (entrypoint / api / service / core /
data / ui / util / tests / config / docs) — inferred heuristically, no LLM.
The signature query: focus
Give it a task, a file, or a symbol name and a token budget. It seeds a personalised PageRank on whatever the query matches, then admits the highest-ranked nodes until the budget is spent — returning exactly the context worth loading, and nothing else:
$ veridge focus "personalised pagerank ranking" . --budget 400
focus 'personalised pagerank ranking' · 24 nodes · ~391/400 tokens
seeds: veridge/rank.py#pagerank, tests/test_rank_budget.py#test_personalised_pagerank...
0.1487 veridge/rank.py#pagerank [symbol, deg 8]
0.0334 veridge/query.py#focus [symbol, deg 10]
0.0289 veridge/query.py#project_map [symbol, deg 9]
0.0243 veridge/budget.py [file, deg 8]
...
Blast-radius: impact
"If I change this, what breaks — and what's the minimal context to review it safely?" That's reverse reachability over the call/import/reference graph, so Veridge answers it for free and exactly — no LLM call, no token cost. The affected set is ranked by a proximity-weighted PageRank and trimmed to a token budget, so even a hub with hundreds of dependents returns its most important ones:
$ veridge impact veridge/model.py . --budget 300
impact (dependents) of 'veridge/model.py' · 82 affected by
showing 20 · ~290/300 tokens
0.0256 d2 veridge/query.py#impact [symbol]
0.0239 d1 veridge/query.py [file]
0.0226 d1 veridge/cli.py [file]
...
d1/d2 is the propagation distance. Use --diff to seed from your working changes
(git diff --name-only HEAD) — "the blast-radius of what I'm about to commit" — or --deps to
invert the question (what the seed relies on).
Same idea over MCP:
pip install -e ".[mcp]"
veridge-mcp . # serves project_map / focus / impact / find / neighbors / health over stdio
Seeing it: the offline viewer
veridge view . writes a single self-contained .veridge/view.html — the graph data is
inlined and the renderer is hand-written vanilla JS on a <canvas>, so there's no CDN, no
bundled library and no server. Double-click it and it opens straight from disk, offline: nodes
coloured by kind, a toggleable legend, search, drag/zoom, and a click-through detail panel.
veridge view . # the whole project (auto-backbones large graphs)
veridge view . --focus "auth flow" # render only the relevant subgraph for a task
--focus renders exactly the slice an assistant would get from veridge focus — so a human can
see the context the agent works from.
Build on it: the open graph
Veridge is meant to be a substrate, not a silo: the deterministic structural + ranking layer
that other tools — an agent, a notebook, a visualiser, an LLM-comprehension tool — build on. The
graph is a small, versioned .veridge/graph.json (documented in
docs/graph-format.md), and you can export it for anyone to consume:
veridge export . --format jgf # JSON Graph Format (generic, tool-friendly)
veridge export . --format dot # Graphviz DOT (for rendering)
veridge export . --format native # the canonical graph.json
So an LLM-comprehension tool doesn't have to spend tokens re-deriving structure — it can take Veridge's ranked graph for free and spend its model only on the semantic layer on top.
How it works
- Index (read-only) — walk the project; classify each file; extract symbols, imports
and calls — Python via the stdlib
ast(zero-deps core), and JS/TS/Go/Rust/Java via the optional[treesitter]extra, both feeding one cross-language call graph; extract doc references (markdown links,[[wikilinks]], and plain path mentions in prose — the part generic tools miss); pull out decision ids (ADR-N/RFC-N/D-X-N); add git sessions. Everything lands in one typed graph with indexed adjacency, so queries are O(degree), not O(edges). - Rank — PageRank over the type-weighted, undirected graph; personalised PageRank for task-aware queries.
- Serve — compact, contents-free rows, selected to fit a token budget. An assistant queries; a human reads the digest.
- Stay fresh — a content-hash manifest diffs the tree, so drift is loud (
gate) and can fix itself:veridge watchrebuilds on change, andveridge install-hookkeeps the map current after every commit.
The graph never duplicates file contents; .veridge/ is derived and always regenerable.
Design principles (please keep these intact)
read-only · zero-deps core · low-token · ranked · deterministic. Determinism matters: nodes
and edges are sorted on serialization, so graph.json is reproducible and diffs are clean.
Status & roadmap
Alpha. Working today: the unified graph (files + symbols + areas + decisions + sessions),
multi-language symbols (Python in the core; JS/TS/Go/Rust/Java via the optional
[treesitter] extra), the PageRank ranking, the token-budgeted focus query, veridge impact (deterministic blast-radius, incl. --diff mode), deterministic comprehension
(map layers, veridge tour, veridge why), the offline graph viewer (veridge view,
with --focus mode), the anti-drift gate with live freshness (veridge watch /
install-hook), the CLI and the optional MCP server. The functional roadmap (Phases 0–5) is
shipped; see ROADMAP.md for what's next.
Development
pip install -e ".[dev,mcp,treesitter]"
ruff check veridge tests
pytest -q
Contributions are welcome — see CONTRIBUTING.md and the design principles (read-only, zero-deps core, low-token, ranked, deterministic).
License
MIT.
Recommended Servers
playwright-mcp
A Model Context Protocol server that enables LLMs to interact with web pages through structured accessibility snapshots without requiring vision models or screenshots.
Magic Component Platform (MCP)
An AI-powered tool that generates modern UI components from natural language descriptions, integrating with popular IDEs to streamline UI development workflow.
Audiense Insights MCP Server
Enables interaction with Audiense Insights accounts via the Model Context Protocol, facilitating the extraction and analysis of marketing insights and audience data including demographics, behavior, and influencer engagement.
VeyraX MCP
Single MCP tool to connect all your favorite tools: Gmail, Calendar and 40 more.
graphlit-mcp-server
The Model Context Protocol (MCP) Server enables integration between MCP clients and the Graphlit service. Ingest anything from Slack to Gmail to podcast feeds, in addition to web crawling, into a Graphlit project - and then retrieve relevant contents from the MCP client.
Kagi MCP Server
An MCP server that integrates Kagi search capabilities with Claude AI, enabling Claude to perform real-time web searches when answering questions that require up-to-date information.
E2B
Using MCP to run code via e2b.
Neon Database
MCP server for interacting with Neon Management API and databases
Exa Search
A Model Context Protocol (MCP) server lets AI assistants like Claude use the Exa AI Search API for web searches. This setup allows AI models to get real-time web information in a safe and controlled way.
Qdrant Server
This repository is an example of how to create a MCP server for Qdrant, a vector search engine.