mcp-agent-opt
Provides code-aware context compression by stripping comments, docstrings, and whitespace while maintaining full logic fidelity for AI agents. It features tools for architectural mapping, symbol searching, and token-budgeted multi-file reading.
README
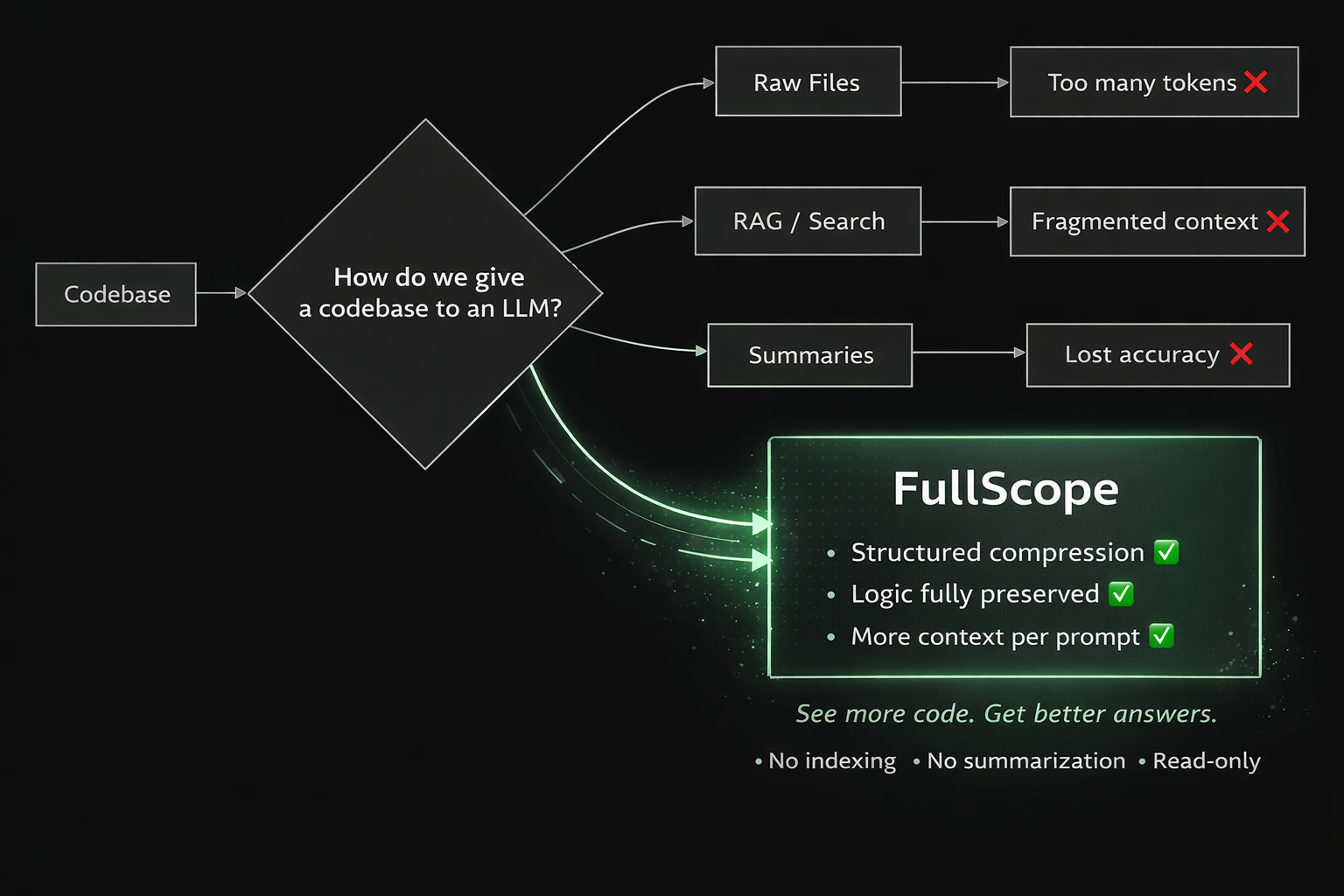
 FullScope
FullScope
See more code. Get better answers.
A context optimization layer for LLMs that enables full-codebase reasoning without losing logic or requiring indexing.
FullScope compresses code structurally so LLMs can process significantly more context — without losing executable logic.
Why this exists
LLMs struggle with real-world codebases. You're forced into tradeoffs:
- Read full files -- too many tokens
- Use search/RAG -- lose global context
- Use summaries -- lose accuracy
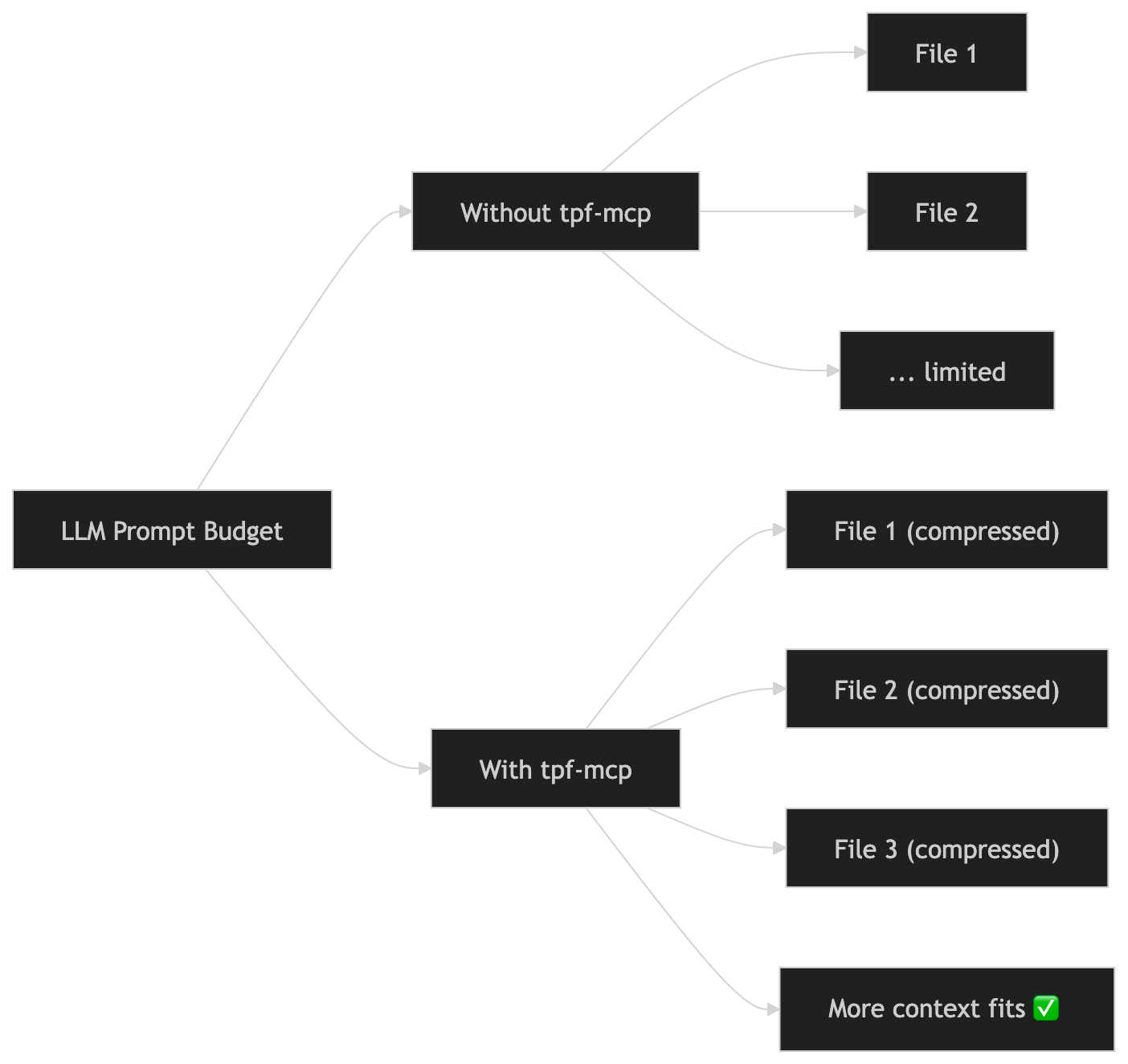
FullScope removes that tradeoff. It reduces token usage without rewriting or abstracting your code, allowing models to reason over entire files and larger portions of your project at once.
The result: better answers, not just smaller inputs.
What this enables
- Understand full modules instead of fragments
- Trace logic across functions and files
- Refactor with complete context
- Debug with full visibility
- Onboard faster to unfamiliar codebases
In practice, context mode lets models read ~2x more code per prompt. Skeleton mode enables ~5x for architecture review. Actual multiplier depends on file shape and comment density.

What makes this different
| FullScope | RAG/Search | Summarization | |
|---|---|---|---|
| Preserves executable logic | Yes | Partial | No |
| Whole-file reasoning | Yes | No (fragments) | No (lossy) |
| Zero risk to code | Yes (read-only, SHA-256 verified) | Yes | Yes |
| Requires indexing | No | Yes | Sometimes |
| Deterministic output | Yes | Varies | No |
What this is not: not a replacement for RAG or search. Not a code editing agent. Not a summarization tool. FullScope is a context amplifier -- it improves how LLMs reason, not how they retrieve or modify code.
Quick Start (60 seconds)
- Add to your MCP config:
{
"mcpServers": {
"fullscope": {
"command": "npx",
"args": ["-y", "fullscope"]
}
}
}
- Ask your agent:
Use fullscope_project to understand this repo
- Pick any file from the project tree and:
Show me the skeleton of index.js
- Drill into a function:
Expand fn:login from that file
How it works
FullScope gives models three levels of code visibility:
| Mode | What the LLM sees | What's stripped |
|---|---|---|
| Context | Full logic, original line numbers | Comments, docstrings, types, whitespace |
| Skeleton | Structure only (signatures, imports, expand handles) | All function/class bodies |
| Expand | One function's full logic | Everything else in the file |
The agent chooses its minification level per file, per call. Start with skeleton (cheapest), expand only what you need, use context for full logic review.
Task demo: "How does login work?"
Raw read: 1 call, 1,060 tokens
FullScope flow: 2 calls, 431 tokens (59% saved)
Representative excerpt from Step 1 -- fullscope_skeleton (180 tokens):
import { db } from './db';
import { hash, verify } from './crypto';
import jwt from 'jsonwebtoken';
const ACCESS_TOKEN_EXPIRY = '15m';
const MAX_LOGIN_ATTEMPTS = 5;
export class AuthService extends EventEmitter { /* 319 lines -- expand: fn:AuthService */ }
Step 2 -- fullscope_expand fn:login (251 tokens): returns the 85-line login method with comments stripped.
Same answer. 59% fewer tokens. 2 targeted calls instead of 1 bulk read.
Try it: npx fullscope --demo
Real savings
Benchmarked on 30 files (30,830 lines) across 5 open-source projects and 16 bundled fixtures. Reproducible: npm run benchmark
No modifications were made to source files — all benchmarks run on unedited upstream code.
External projects (not our code)
| File | Source | Lang | Lines | Context | Skeleton |
|---|---|---|---|---|---|
| applications.py | FastAPI | Python | 4,692 | 78% | 99% |
| routing.py | FastAPI | Python | 4,957 | 68% | 94% |
| defs.rs | Ripgrep | Rust | 7,780 | 4% | 47% |
| walk.rs | Ripgrep | Rust | 2,495 | 51% | 30% |
| controller_utils.go | Kubernetes | Go | 1,461 | 46% | 40% |
| controller_ref_manager.go | Kubernetes | Go | 597 | 56% | 41% |
| fluentd-gcp-configmap.yaml | Kubernetes | YAML | 466 | 0% | 0% |
| response.js | Express | JS | 1,048 | 68% | 88% |
| application.js | Express | JS | 632 | 99% | 82% |
| item.py | python-projects | Python | 484 | 65% | 96% |
| main.py (Chess) | python-projects | Python | 662 | 1% | 89% |
Selected to represent different languages, coding styles, and file types:
- Express / FastAPI — heavily documented, high comment density (best case for context)
- Kubernetes — production Go with moderate comments + real YAML config
- Ripgrep — dense Rust systems code with doc comments (tests large files)
- python-projects — varied beginner code (tests minimal-comment worst case)
Bundled fixtures (16 files)
Includes: JavaScript, TypeScript, Python, Rust, Go, Java, C#, JSON, YAML, TOML, Markdown, HTML, CSS, log files, and broken/malformed edge cases.
Summary
| Scope | Files | Lines | Context | Skeleton |
|---|---|---|---|---|
| External code (5 projects) | 14 | 28,063 | 44% | 64% |
| Bundled fixtures (7 langs + docs) | 16 | 2,767 | 23% | 41% |
| Combined | 30 | 30,830 | 42% | 62% |
Tested across code, config, documentation, and logs.
Task-level benchmarks
| Task | Baseline | FullScope | Savings | Result |
|---|---|---|---|---|
| Explain how login works | 1,060 tokens (1 call) | 431 tokens (2 calls) | 59% | Pass |
| Find symbol usages | 3,155 tokens (3 calls) | 318 tokens (1 call) | 90% | Pass |
| Orient in new repo | 1,740 tokens (3 calls) | 246 tokens (1 call) | 86% | Pass |
| Inspect Python handler | 953 tokens (1 call) | 590 tokens (1 call) | 38% | Pass |
| Verify line before edit | 1,060 tokens (1 call) | 66 tokens (1 call) | 94% | Pass |
Estimated 30-file session: ~32,700 tokens saved (~$0.49 at $15/1M).
When savings are low
Savings are minimal when files have few comments (Rust: 4-51%), are mostly data/config (JSON/YAML: 0%), or have no function bodies to collapse (C# property classes: 0% skeleton). In these cases, FullScope prioritizes fidelity over minification.
Token counts are estimated using a lightweight word-count heuristic, not a production tokenizer. Relative savings remain accurate.
Install
Claude Code
// .mcp.json or ~/.claude/settings.json
{
"mcpServers": {
"fullscope": {
"command": "npx",
"args": ["-y", "fullscope"]
}
}
}
Cursor
Settings > Features > MCP > Add New MCP Server
- Name:
fullscope/ Type:command/ Command:npx -y fullscope
VS Code Copilot
// .vscode/mcp.json
{
"servers": {
"fullscope": {
"command": "npx",
"args": ["-y", "fullscope"]
}
}
}
Gemini CLI
// ~/.gemini/settings.json
{
"mcpServers": {
"fullscope": {
"command": "npx",
"args": ["-y", "fullscope"]
}
}
}
Tools (9)
Orientation
fullscope_project -- Codebase overview in one call. Returns filtered directory tree (.gitignore-aware), compressed config files, git status, detected entry points with critical-path dependencies.
Progressive disclosure
fullscope_skeleton -- Signatures-only view. Shows function/class signatures with bodies replaced by expand handles. Detects standalone functions, class methods, and property-assigned functions (e.g. const handler = () => {}). Includes IMPORTS and EXPORTS summary.
fullscope_expand -- Per-function drill-down. Takes an expand handle from skeleton output (e.g. fn:login or fn:AuthService.login for class methods). Supports multi-line signatures. Returns just that function body with context-level compression.
fullscope_context -- Compressed full-file read. Strips comments, docstrings, types, whitespace. Preserves all logic with original line numbers and virtual markers showing where content was stripped. Supports mode: "schema" for JSON files (keys+types only) and diff: true for compact re-read diffs.
Multi-file
fullscope_batch_context -- Read multiple files in one call. Supports intent parameter (preserves lines matching intent keywords), token budgeting (auto-downshifts to skeleton), cross-file import dedup, and dependency-ordered output.
Discovery
fullscope_search -- Compressed grep via ripgrep. Filters results through language recipes. Path compaction strips the project root.
fullscope_usages -- Symbol usage finder. Searches for per-language import patterns and call sites. Results grouped by file, imports distinguished from usages.
Safety
fullscope_verify_line -- Confirms raw file content at a given line number. Optionally accepts expected content for explicit match verification before editing.
fullscope_stats -- Session savings tracker. Shows files compressed, tokens saved, estimated cost savings, and context-rot warnings.
Safety and integrity
FullScope is read-only by design. It cannot corrupt your code because it never opens a file for writing.
- Never modifies, patches, or rewrites source files
- Never executes code or sends data externally
- If minification fails, raw content is returned unchanged
- Search uses argument arrays, not shell interpolation (injection-safe)
Verified: 0 byte-level file changes across 203 operations on 34 files, confirmed by SHA-256 hashing before and after every operation. See docs/INTEGRITY.md.
Every compressed output includes:
COMPRESSED VIEW -- do not use these line numbers for editing. Read the raw file before applying changes.
When NOT to use this
- Editing a file -- use the built-in read tool (exact content needed for search/replace)
- Exact formatting matters -- comments and whitespace are stripped
- You need type annotations -- TypeScript types are removed in skeleton mode
FullScope is for reading and understanding, not editing.
Supported languages
Tier 1 (recipe + skeleton): JavaScript, TypeScript, Python, Rust, Go, Java, C#, C/C++
Tier 2 (recipe only): Ruby, PHP, Swift, Kotlin, Scala, HCL/Terraform
Tier 3 (docs + data): Markdown, JSON (compact + schema modes), YAML, TOML, HTML, CSS, XML, config files, log files (with line dedup)
Requirements
- Node.js 18+ (developed and tested on v24)
- ripgrep (
rg) recommended for search/usages (falls back togrep) - Python 3 optional -- improves Python skeletonization (regex fallback available)
- esbuild optional -- improves TypeScript type-stripping (installed as optional dependency)
Limitations
- Compressed output is for reading, not editing. Always use raw reads before making changes.
- Skeletonization is heuristic. C-family languages use brace-depth counting, which can break on complex macros or
#ifdefnesting. Property-assigned functions and class methods are detected via pattern matching. Tree-sitter support is planned. - Intent filtering is keyword-based, not semantic ranking.
- Diff cache is session-local (in-memory only, opt-in via
diff: true). - Savings vary by code style. Comment-heavy code (FastAPI: 78%) saves far more than minimal-comment code (Rust: 8-13%).
- Skeleton savings depend on structure. Files without functions (data/config) see minimal benefit.
- Line-number recovery is heuristic. Text matching after compression is verified for common patterns but could mis-anchor on files with many repeated identical lines. Use
fullscope_verify_lineto confirm before editing.
Verification
npm test # 271 tests across 17 files
npm run benchmark # File + task benchmarks across 30 files
npm run task-benchmark # 5 real tasks, all passing, avg 76% savings
npm run verify-integrity # SHA-256 hash verification (34 files, 203 ops)
npx fullscope --demo # Live demo: skeleton -> expand -> 59% savings on the bundled auth fixture
All results committed to data/ (benchmarks.json, task-benchmark.json, integrity-results.json).
Full documentation:
- docs/INTEGRITY.md -- integrity proof with actual SHA-256 hashes
- docs/TEST_MATRIX.md -- complete test coverage matrix
- examples/auth-service-demo.md -- before/after task comparison
- SECURITY.md -- design guarantees
- CHANGELOG.md -- v0.1.1 release notes
Development
npm install
npm test
npm run benchmark
npm run verify-integrity
Author
Built by Adi Levinshtein.
If you use this in a product, attribution is appreciated.
License
MIT
Recommended Servers
playwright-mcp
A Model Context Protocol server that enables LLMs to interact with web pages through structured accessibility snapshots without requiring vision models or screenshots.
Magic Component Platform (MCP)
An AI-powered tool that generates modern UI components from natural language descriptions, integrating with popular IDEs to streamline UI development workflow.
Audiense Insights MCP Server
Enables interaction with Audiense Insights accounts via the Model Context Protocol, facilitating the extraction and analysis of marketing insights and audience data including demographics, behavior, and influencer engagement.
VeyraX MCP
Single MCP tool to connect all your favorite tools: Gmail, Calendar and 40 more.
graphlit-mcp-server
The Model Context Protocol (MCP) Server enables integration between MCP clients and the Graphlit service. Ingest anything from Slack to Gmail to podcast feeds, in addition to web crawling, into a Graphlit project - and then retrieve relevant contents from the MCP client.
Kagi MCP Server
An MCP server that integrates Kagi search capabilities with Claude AI, enabling Claude to perform real-time web searches when answering questions that require up-to-date information.
E2B
Using MCP to run code via e2b.
Neon Database
MCP server for interacting with Neon Management API and databases
Exa Search
A Model Context Protocol (MCP) server lets AI assistants like Claude use the Exa AI Search API for web searches. This setup allows AI models to get real-time web information in a safe and controlled way.
Qdrant Server
This repository is an example of how to create a MCP server for Qdrant, a vector search engine.